好程序员-千锋教育旗下高端IT职业教育品牌
官方微信
2021-02-04
flink教程 好程序员大数据培训 大数据教程
在当前数据量激增传统的时代,不同的业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如何进行有效地处理,成为当下大多数公司所面临的问题。企业需要能够同时支持高吞吐、低延迟、高性能的流处理技术来处理日益增长的数据。
相对于传统的数据处理模式,流式数据处理则有着更高的处理效率和成本控制。Apache Flink就是近年来在开源社区发展不断发展的能够支持同时支持高吞吐、低延迟、高性能分布式处理框架。
Flink在近年来逐步被人们所熟知和使用,其主要原因不仅因为提供同时支持高吞吐、低延迟和exactly-once语义的实时计算能力,同时Flink还提供了基于流式计算引擎处理批量数据的计算能力,真正意义实现了批流统一,同时随着Alibaba对Blink的开源,极大地增强了Flink对批计算领域的支持。
目前在全球范围内,越来越多的公司开始使用Flink,在国内比较出名的互联网公司如Alibaba,美团,滴滴等,都在大规模的使用Flink作为企业的分布式大数据处理引擎。
到底什么Flink?今天圆圆就带大家认识一下:
一、什么是Flink?
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。
Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
用图表示就是这样的:
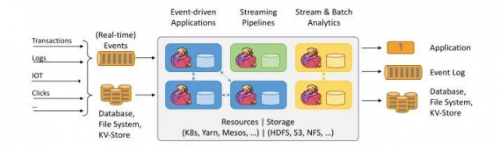
上图大致可以分为三块内容:左边为数据输入、右边为数据输出、中间为Flink数据处理。
Flink支持消息队列的Events(支持实时的事件)的输入,上游源源不断产生数据放入消息队列,Flink不断消费、处理消息队列中的数据,处理完成之后数据写入下游系统,这个过程是不断持续的进行。
二、Flink都有哪些优势?
1.同时支持高吞吐、低延迟、高性能
Flink是一套集高吞吐,低延迟,高性能三者于一身的分布式流式数据处理框架。
非常成熟的计算框架Apache Spark也只能兼顾高吞吐和高性能特性,在Spark Streaming流式计算中无法做到低延迟保障;而Apache Storm只能支持低延迟和高性能特性,但是无法满足高吞吐的要求。而对于满足高吞吐,低延迟,高性能这三个目标对分布式流式计算框架是非常重要的。
2.支持事件时间(Event Time)概念
在流式计算领域中,窗口计算的地位举足轻重,但目前大多数计算框架窗口计算所采用的都是系统时间(Process Time),也是事件传输到计算框架处理时,系统主机的当前时间,Flink能够支持基于事件时间(Event Time)语义的进行窗口计算,就是使用事件产生的时间,这种时间机制使得事件即使无序到达甚至延迟到达,数据流都能够计算出精确的结果,同时保持了事件原本产生时的在时间维度的特点,而不受网络传输或者计算框架的影响。
3.支持有状态计算
Flink在1.4版本中实现了状态管理,所谓状态就是在流式计算过程中将算子的中间结果数据的保存在内存或者DB中,等下一个事件进入接着从状态中获取中间结果进行计算,从而无需基于全部的原始数据统计结果,这种做法极大地提升了系统的性能,同时也降低了计算过程的耗时。
对于数据量非常大且逻辑运算非常复杂的流式运算,基于状态的流式计算则显得非常使用。
4.支持高度灵活的窗口(Window)操作
在流处理应用中,数据是连续不断的,需要通过窗口的方式对流数据进行一定范围的聚合计算,例如统计在过去的1分钟内有多少用户点击了某一网页,在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据再进行计算。
Flink将窗口划分为基于Time、Count、Session,以及Data-driven等类型的窗口操作,窗口能够用灵活的触发条件定制化从而达到对复杂的流传输模式的支持,不同的窗口操作应用能够反馈出真实事件产生的情况,用户可以定义不同的窗口触发机制来满足不同的需求。
5.基于轻量级分布式快照(Snapshot)实现的容错
Flink能够分布式运行在上千个节点之上,将一个大型计算的流程拆解成小的计算过程,然后将计算过程分布到单台并行节点上进行处理。
在任务执行过程中,能够自动的发现事件处理过程中的错误而导致数据不一致的问题,常见的错误类型例如:节点宕机,或者网路传输问题,或是由于用户因为升级或修复问题而导致计算服务重启等。
在这些情况下,通过基于分布式快照技术的Checkpoints,将执行过程中的任务信息进行持久化存储,一旦任务出现异常宕机,Flink能够进行任务的自动恢复,从而确保数据在处理过程中的一致性。
6.基于JVM实现独立的内存管理
内存管理是每套计算框架需要重点考虑的领域,尤其对于计算量比较大的计算场景,数据在内存中该如何进行管理,针对内存管理这块,Flink实现了自身管理内存的机制,尽可能减少Full GC对系统的影响。
另外通过自定义序列化/反序列化方法将所有的对象转换成二进制在内存中存储,降低数据存储的大小,更加有效的对内存空间进行利用,降低GC所带来的性能下降或者任务停止的风险,同时提升了分布式处理过数据传输的性能。
因此Flink较其他分布式处理的框架则会显得更加稳定,不会因为JVM GC等问题而导致整个应用宕机的问题。
正是由于Flink的这些优势,也吸引了众多的企业参与研发和使用Flink这项技术。
因此,大家也都把Flink称为:下一代大数据处理框架的标准。
既然Flink在大数据处理中那么重要,那么该如何入门学习呢?
圆圆今天就为大家带来了《好程序员2020全套Flink教程(共400集)》,教程中除了视频之外,还配有全套源码+笔记,让大家学习无忧!
三、好程序员2020年Flink教程—课程介绍
1.课程内容
本课程涵盖Flink概念、Flink介绍、初识Flink代码开发、Flink集群部署&运行时架构、Flink流处理API、Flink Connector、Flink高级特性、Flink window和time操作、Flink Tale API & SQL、Flink CEP等知识点。该套课程深度剖析了时下热门的流处理框架之Flink ,你值得拥有。
2.通过本课程你可以学到哪些知识?
学完本课程,你可以完全掌握Flink批处理和流处理、掌握时间和窗口计算、掌握Flink常用的Connector、掌握延迟数据处理之WaterMark水位线机制、掌握Flink状态管理和容错机制、掌握Flink的部署模式和高可用配置等。
3.适合哪些人学习?
本套课程适合有一定大数据基础的同学学习。
4.好程序员2021年Flink学习路线
课程目录
第1章-Flink介绍、初识Flink代码开发
1.01 讲师个人介绍
1.02 Flink课程内容概述
1.03 Flink前世今生
1.04 Flink定义
1.05 Flink在全球的热度
1.06 Flink在国内企业中的应用
1.07 为什么选择Flink
1.08 哪些行业需要处理流式数据
1.09 传统数据处理结构之事务处理
1.10 传统数据处理结构之分析处理
1.11 Flink中有状态的流式处理
1.12 流处理演变之Lamda架构
1.13 流处理技术的演变
1.14 Flink的主要特点之事件驱动型应用
1.15 Flink的主要特点之基于流的世界观
1.16 Flink的主要特点之分层API
1.17 Flink的其他特点
1.18 Flink vs Spark Streaming特点概述
1.19 Flink & Spark Streaming之数据模型以及运行时架构对比说明
1.20 Flink的应用场景之数据分析应用
1.21 Flink的应用场景之数据管道应用
1.22 Flink之前版本(<1.9.0)的架构图
1.23 Flink当前版本(≥1.9.0)的架构图
1.24 Flink中的流处理与批处理
1.25 Flink项目相关的maven依赖详解
1.26 初识Flink代码开发之pom依赖
1.27 有界流开发业务分解
1.28 有界流开发之代码轮廓搭建
1.29 有界流开发详解以及效果演示
1.30 有界流开发总结
第2章-初识Flink代码开发、Flink集群部署以及运行时架构
2.31 上堂课知识点回顾
2.32 WordCount案例之源在本地目的地在hdfs前期准备
2.33 WordCount案例之源在本地目的地在hdfs核心代码书写以及效果演示
2.34 WordCount案例之源在本地目的地在hdfs总结
2.35 WordCount案例之源在hdfs目的地在本地核心代码书写以及效果演示
2.36 WordCount案例之源在hdfs目的地在本地总结
2.37 WordCount案例之源在hdfs目的地在hdfs核心代码书写以及效果演示
2.38 WordCount案例之源在hdfs目的地在hdfs总结
2.39 WordCount案例之代码优化以及效果演示
2.40 WordCount案例之代码优化总结
2.41 无界流之WordCount案例说明
2.42 无界流之WordCount案例源码以及效果演示
2.43 无界流之WordCount案例总结
2.44 无界流之WordCount案例优化以及效果演示
2.45 无界流之WordCount案例总结
2.46 Flink应用部署模式介绍
2.47 Flink应用部署之local模式实操
2.48 Flink应用部署之local模式实操Ⅱ
2.49 Flink应用部署之local模式实操Ⅲ
2.50 Flink应用部署local模式之命令行方式总结
2.51 Flink应用部署local模式之可视化部署方式说明
2.52 Flink应用部署local模式之可视化部署方式演示
2.53 Flink应用部署local模式之可视化部署方式总结
2.54 Flink应用部署之standalone方式说明
2.55 Flink分布式集群搭建实操
2.56 Flink分布式集群搭建总结
2.57 flink应用部署到Flink分布式集群之命令行方式实操
2.58 flink应用部署到Flink分布式集群之命令行方式总结
2.59 flink应用部署到Flink分布式集群之可视化方式演示
2.60 flink应用部署到Flink分布式集群之可视化方式总结
第3章-Flink集群部署以及运行时架构
3.61 上堂课知识点回顾
3.62 Standalone模式任务调度原理
3.63 Flink Standalone HA说明
3.64 Flink Standalone HA实操
3.65 Flink Standalone HA验证
3.66 Flink Standalone HA总结1
3.67 Flink Standalone HA总结2
3.68 Flink应用部署模式之Flink On Yarn介绍
3.69 Flink On Yarn两种具体实现方式之session、per job详解
3.70 session方式实操
3.71 上午知识点回顾
3.72 将Flink应用部署到session中实操
3.73 将Flink应用部署到session中总结
3.74 session部署方式集群的停止
3.75 Per Job方式介绍
3.76 Per Job方式实操
3.77 Per Job方式总结
3.78 Flink On Yarn内部实现
3.79 Flink On Yarn内部实现之类比说明
3.80 JobManager进程的HA介绍
3.81 JobManager进程的HA介绍
3.82 JobManager进程的HA实操1
3.83 JobManager进程的HA实操2
3.84 JobManager进程的HA最终效果演示
第4章-Flink运行时架构以及Flink流处理API
4.085 上堂课知识点回顾
4.086 Flink On Yarn模式之运行时组件
4.087 Flink运行时组件之作业管理器JobManager
4.088 Flink运行时的组件之任务管理器TaskManager
4.089 Flink运行时的组件之资源管理器ResourceManager
4.090 Flink运行时的组件之分发器Dispatcher
4.091 从高层级的视角详解任务提交流程
4.092 Flink On Yarn任务提交流程总结
4.093 TaskManager和Slots
4.094 TaskManager和Slots深度剖析
4.095 Flink应用并行度的设置
4.096 程序与数据流
4.097 程序与数据流详解
4.098 DataFlow中的Oprator与程序中的Transformation关系实操
4.099 ataFlow中的Oprator与程序中的Transformation关系总结
4.100 堂课知识点回顾
4.101 执行图
4.102 执行图四层详解
4.103 并行度
4.104 并行度图解
4.105 Stream在算子之间传输数据的形式
4.106 任务链Oprator Chain
4.107 任务链Oprator Chain实操以及总结
4.108 任务链生成图解
4.109 使用无界流API进行离线计算实操
4.110 使用无界流API进行离线计算总结
4.111 Flink 流处理API之Enviroment
4.112 DataStream API概述
4.113 DataSet API概述
4.114 DataStream Source API之从集合中读取数据实操
4.115 DataStream Source API之从集合中读取数据总结
第5章-Flink流处理API
5.116 上堂课知识点回顾1
5.117 上堂课知识点回顾2
5.118 Source案例之从文件读取数据实操
5.119 Source案例之从文件读取数据总结
5.120 以kafka消息队列中的数据作为来源介绍
5.121 以kafka消息队列中的数据作为来源案例之前期准备
5.122 以kafka消息队列中的数据作为Source案例实操
5.123 以kafka消息队列中的数据作为Source案例效果演示以及总结
5.124 自定义Source介绍
5.125 自定义Source实操之代码轮廓搭建
5.126 SourceFunction自定义子类核心源码书写以及效果演示
5.127 自定义Source案例总结
5.128 DataStream Transformation API之map、flatMap、filter和keyBy介绍
......
第18章-Window和Time操作、CEP
18.379 上堂课知识点回顾Ⅰ
18.380 上堂课知识点回顾Ⅱ
18.381 Watermark总结
18.382 Flink Table API 和 Flink SQL介绍
18.383 Flink Table API使用方式简介
18.384 Flink Table API简单案例实操
18.385 Flink Table API简单案例效果演示以及总结
18.386 给Flink Table API中相应的字段取别名
18.387 使用链式编程方式对Flink Table API编程方式进行优化
18.388 Flink Table API的窗口操作案例说明
18.389 Flink Table API的窗口操作案例实操
18.390 Flink Table API窗口操作效果演示以及总结
18.391 Flink Table API中关于groupBy和时间窗口说明
18.392 Flink Table API之toAppendStream和toRetractStream详解之案例实操
18.393 Flink Table API之toAppendStream和toRetractStream总结
18.394 Flink SQL特点阐述以及使用方式说明
18.395 Flink SQL使用方式案例实操以及效果演示
18.396 Flink SQL使用方式案例总结
18.397 使用Flink SQL API进行窗口操作案例实操以及效果演示
18.398 使用Flink SQL API进行窗口操作案例总结
18.399 使用Flink SQL API实时统计单词出现的次数案例实操以及总结
18.400 Flink Table API 和Flink SQL总结
18.401 Flink CEP介绍
18.402 非确定有限自动机(NFA)
18.403 Flink CEP Library介绍
18.404 Flink CEP案例介绍
18.405 Flink CEP案例之Event类设计
18.406 Flink CEP案例实操Ⅰ
18.407 Flink CEP案例实操Ⅱ之定制CEP Pattern
18.408 Flink CEP案例实操Ⅲ
18.409 Flink CEP案例最终效果演示
18.410 Flink CEP案例总结
18.411 Flink CEP案例优化
18.412 Flink CEP个体模式的条件介绍
18.413 模式序列和模式检测
18.414 匹配事件的提取和超时事件的提取说明
18.415 超时事件处理案例实操Ⅰ
18.416 超时事件处理案例实操Ⅱ
18.417 超时事件处理案例总结
五、教程免费领取方式
关注公众号:好程序员,回复“flink”,即可免费获得《好程序员2021年Flink全套教程(400集)》,想要的小伙伴抓紧时间!

扫码回复“flink”


 扫码开启架构师蜕变之旅 >>
扫码开启架构师蜕变之旅 >>
开班时间:2021-04-12(深圳)
开班盛况开班时间:2021-05-17(北京)
开班盛况开班时间:2021-03-22(杭州)
开班盛况开班时间:2021-04-26(北京)
开班盛况开班时间:2021-05-10(北京)
开班盛况开班时间:2021-02-22(北京)
开班盛况开班时间:2021-07-12(北京)
预约报名开班时间:2020-09-21(上海)
开班盛况开班时间:2021-07-12(北京)
预约报名开班时间:2019-07-22(北京)
开班盛况
Copyright 2011-2023 北京千锋互联科技有限公司 .All Right
京ICP备12003911号-5
 京公网安备 11010802035720号
京公网安备 11010802035720号













