好程序员-千锋教育旗下高端IT职业教育品牌
官方微信
2020-05-29
大数据培训 好程序员
好程序员大数据培训分享Apache-Hadoop简介,一、Hadoop出现的原因:现在的我们,生活在数据大爆炸的年代。国际数据公司已经预测在2020年,全球的数据总量将达到44ZB,经过单位换算后,至少在440亿TB以上,也就是说,全球每人一块1TB的硬盘都存储不下。
一些数据集的大小更远远超过了1TB,也就是说,数据的存储是一个要解决的问题。同时,硬盘技术也面临一个技术瓶颈,就是硬盘的传输速度(读数据的速度)的提升远远低于硬盘容量的提升。我们看下面这个表格:
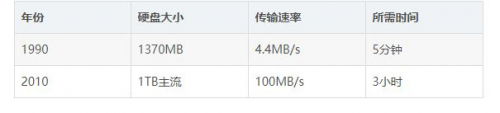
硬盘瓶颈比较
可以看到,容量提升了将近1000倍,而传输速度才提升了20倍,读完一个硬盘的所需要的时间相对来说,更长更久了(已经违反了数据价值的即时性)。读数据都花了这么长时间,更不用说写数据了。
对于如何提高读取数据的效率,我们已经想到解决的方法了,那就是将一个数据集存储到多个硬盘里,然后并行读取。比如1T的数据,我们平均100份存储到100个1TB硬盘上,同时读取,那么读取完整个数据集的时间用不上两分钟。至于硬盘剩下的99%的容量,我们可以用来存储其他的数据集,这样就不会产生浪费。解决读取效率问题的同时,我们也解决了大数据的存储问题。
但是,我们同时对多个硬盘进行读/写操作时,又有了新的问题需要解决:
1、硬件故障问题。一旦使用多个硬件,相对来说,个别硬件产生故障的几率就高,为了避免数据丢失,最常见的做法就是复制(replication):文件系统保存数据的多个复本,一旦发生故障,就可以使用另外的复本。
2、读取数据的正确性问题。大数据时代的一个分析任务,就需要结合大部分数据来共同完成分析,因此从一个硬盘上读取的数据要与从其他99个硬盘上读取的数据结合起来使用。那么,在读取过程中,如何保证数据的正确性,就是一个很大的挑战。
有人会想,既然使用了多个硬盘,为什么不用配有多个硬盘的关系型数据库来进行数据的存储和分析呢?其实,这个主要取决于硬盘发展的一个技术限制,那就是需要寻址操作。我们从关系型数据库中读取数据包含着大量的寻址操作,那么寻址所产生的时间开销必然会大大的增加,再加上读取数据的时间,就更加漫长了。还有一个原因,关系型数据库不适合存储半结构化和非结构化的数据,而这个时代,半结构化和非结构化的数据占90%,而结构化数据只占10%。
针对于上述几个问题,Hadoop为我们提供了一个可靠的且可扩展的存储和分析平台,此外,由于Hadoop运行在商用硬件上且是开源的,因此Hadoop的使用成本是比较低了,在用户的承受范围内。
Hadoop是Apache基金会旗下的一个开源的分布式计算平台,是基于Java语言开发的,有很好的跨平台特性,并且可以部署在廉价的计算机集群中。用户无需了解分布式底层细节,就可以开发分布式程序,充分利用集群的威力进行高速运算和存储。
最初,Hadoop的核心技术是HDFS和MapReduce。
HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的简称,它具有较高的读写速度,很好的容错性和可伸缩性,为海量的数据提供了分布式存储,其冗余数据存储的方式很好的保证了数据的安全性。
MapReduce是一种用于并行处理大数据集的软件框架(编程模型)。用户可在无需了解底层细节的情况下,编写MapReduce程序进行分析和处理分布式文件系统上的数据,MapReduce保证了分析和处理数据的高效性。
因其在分布式环境下提供了高效的,海量的数据的优秀处理能力,Hadoop被公认为大数据行业中的标准开源软件。几乎所有主流的厂商如谷歌,雅虎,微软,淘宝等等这样的大公司都是围绕Hadoop进行提供开发工具,开源软件,商业化工具或技术服务的。
在Hadoop2.0以后,又引入了另一个核心技术:YARN(Yet Another Resource Negotiator)。它是一个任务调度和集群资源管理系统,主要有两类长期运行的守护线程来提供自己的核心服务:一类是用于管理集群上资源使用的资源管理器(Resouce Manager),另一类是运行在集群中各个节点上且能够启动和监控容器(container)的节点管理器(Node Manager)。
发展到现在的Hadoop3.x可以概括成以下五个模块:
关于Hadoop这个名字的由来,该项目的创建者Doug Cutting是这样解释的:“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子恰恰是这方面的高手。”
Hadoop的发音是 [hædu:p]。
Hadoop由知名项目Apache Lucene的创始人道格·卡丁(doug Cutting)创建。
Hadoop因为是基于Java语言开发的,因此最理想的运行平台就是Linux系统了。它也支持多种编程语言,如C++,PHP等等。
也可以总结出以下优点:
上一篇:好程序员大数据培训分享大数据概述
下一篇:好程序员大数据培训分享大数据概念


 扫码开启架构师蜕变之旅 >>
扫码开启架构师蜕变之旅 >>
开班时间:2021-04-12(深圳)
开班盛况开班时间:2021-05-17(北京)
开班盛况开班时间:2021-03-22(杭州)
开班盛况开班时间:2021-04-26(北京)
开班盛况开班时间:2021-05-10(北京)
开班盛况开班时间:2021-02-22(北京)
开班盛况开班时间:2021-07-12(北京)
预约报名开班时间:2020-09-21(上海)
开班盛况开班时间:2021-07-12(北京)
预约报名开班时间:2019-07-22(北京)
开班盛况
Copyright 2011-2023 北京千锋互联科技有限公司 .All Right
京ICP备12003911号-5
 京公网安备 11010802035720号
京公网安备 11010802035720号













